Analogy: LLMs as CISC, MoE as RISC
Background, what's the problem?
The big thing of 2023 has been ever-larger Large Language Models, each of which gets sold as "can do basically everything" (with small print for all the things it can't do). This works very well, but it also needs hardware in the price range "if you have to ask you can't afford it". So, can we do better?
I think we can do better.
If you'll permit a loose analogy, there are two ways you can design a CPU: a huge number of defined instructions that each perform relatively complex actions (CISC), or a small number of defined instructions each of which performs only a simple instruction. As a child of the 80s-90s, my go-to example of this was how Apple presented the PowerPC chips in its late-90s Macs as being better than Intel chips of the same era and clock speed, because PowerPC was RISC and Intel was CISC. (If you're about to ask "Didn't Apple just switch from Intel chips to their own ones based on ARM cores?", yes, they did. Macs started with Motorola, then PowerPC, then Intel, then their mobile chips got better than Intel chips and they switched Macs to the M-series).
LLMs are very large and complex, and perform a huge number of calculations just to get the next "token" (think "word fragment"), and while these are incredibly impressive relative to the previous state of the art for natural language processing, the previous state of the art was terrible. I see them for all their flaws as well as all their strengths, so anyone who tries to argue with me either that they're "just stochastic parrots" or that they're the final missing puzzle piece for The Singularity — no, they're much better than parrots (and also such clichés are humans acting like stochastic parrots themselves), but also no, they're obviously more book-smart than world-smart (I mean, what did you expect, they're a brain the size of a shrew that was given a subjective experience equivalent to reading random websites for 50,000 years).
So, people know about this already, what are they already doing to reduce this?
There's a thing called "Mixture of Experts" (MoE), but we're still very early days with this for now (not chronologically, it's been around for a while, but it's not well developed). Currently, as I understand it, MoE is a collective of (relatively) smaller models, such that only a few of these models are ever executed. So far, so good. But from what I hear from researchers, it's really hard to divide problems between them, both for inference and for training — this shouldn't be too surprising, the inputs can be anything in the input domain (i.e. "things someone could type" for a pure-text chatbot, or that plus pictures if it's supposed to understand images as well).
What do I suggest?
So, that's the statement of where we are and what the problem is; what's my suggestion for a solution, or at least a direction to a soution?
Architecture:
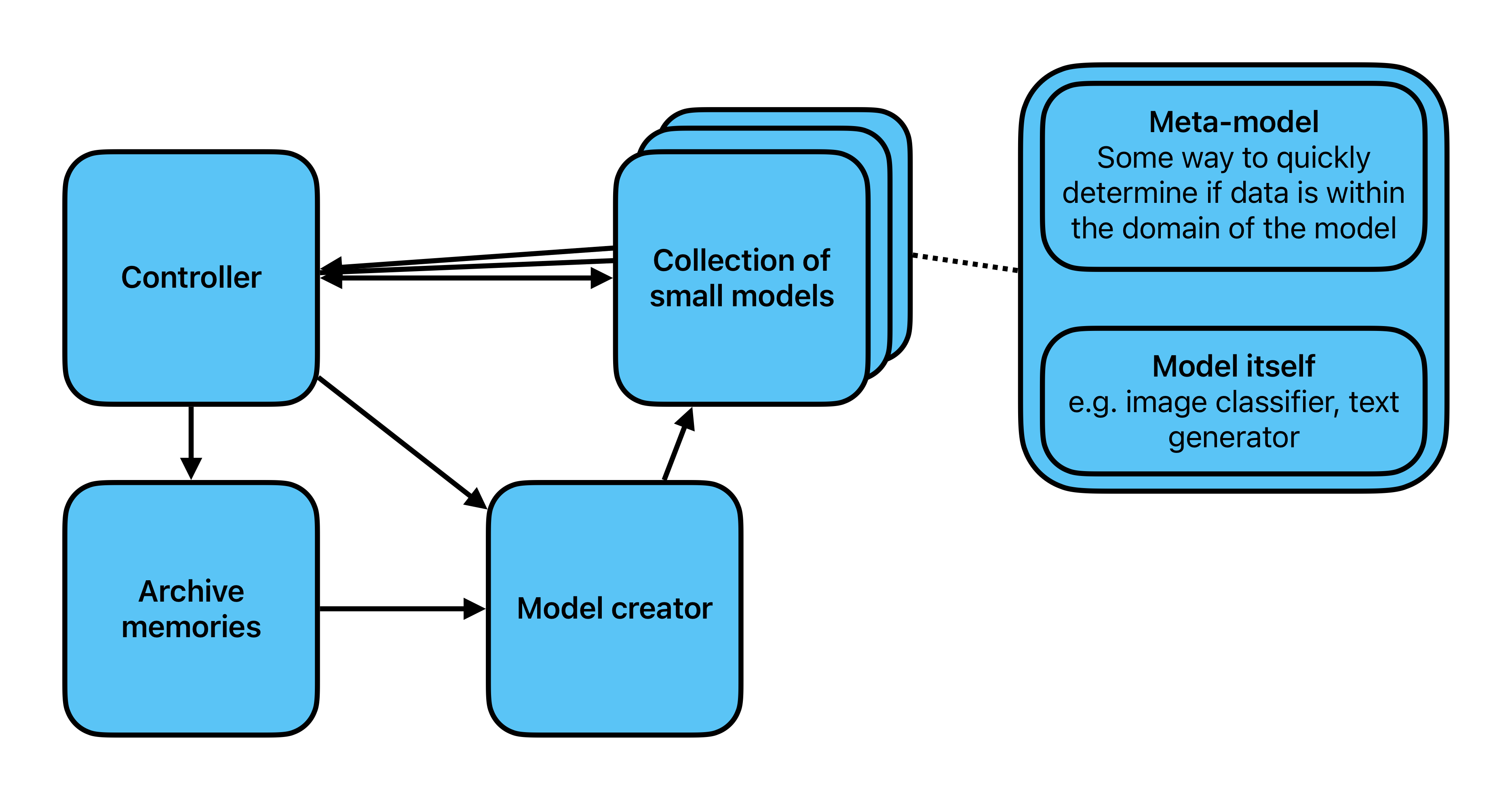
- Controller: Takes the system input, uses it to query the model collection until it finds a model that "knows what to do" with that input, or invokes the model creator when there is none.
- Archive memories: All "important" experiences.
- Model creator: A function which creates new models when no existing model can deal with the input.
- Collection of (relatively) small models — each model consists of:
- A meta-model: a fast running test which says, conditional on the current input experience, whether or not the model should be executed.
- The model itself
There are of course many ways to approach each part of this, and which one is most appropriate is an open question.
For example:
- It could be possible to take either any model whose meta-model says it can understand the data, or whichever model's meta-model is most confident, or take many models which "think they know how to respond" and perform a standard MoE combination of those models. I have yet to explore which would work best.
- At training time (which could be continuous, but doesn't have to be), the controller also needs to have a feedback system which allows whichever model(s) were activated to be improved based on their answer. It may be useful for meta-models which "thought they might know but weren't sure" (i.e. close to the threshold for being included in the set of models which might have answered) also get updated.
- It would also be possible for the model creator could itself be a model, whose meta-model is "all the other model's meta-models can't cope with this".
Note: at time of writing, this represents "things I want to try", I've not written any experiments with this. I intend to start with a toy model, probably the MNIST handwriting set, where each model/meta-model is trying to recognise just one of the digits, and the model creator is a short python script. It would also be possible to explore a similar approach with a much more capable model, such as using a LLM as a controller to query (and via some appropriate API, invoke and use the output of) a database of code functions, and another LLM as a model creator to create new maths functions in some programming language.